
How to Use awk Command in Bash
To effectively manage files, directories, and data in a command-line environment, it is crucial to have a solid understanding of the available commands. One such command is the ‘awk’ command, which offers powerful text processing and manipulation capabilities in Unix/Linux. This article aims to explain what the ‘awk’ command is and how to use it effectively in different scenarios, providing readers with a comprehensive overview of its functionalities. Here I will use the Ubuntu operating system to demonstrate the use of awk command in bash
What is the ‘awk’ Command?
The ‘awk’ command is a versatile utility that offers powerful text processing and manipulation capabilities in Unix/Linux environments. Users can employ it to execute various tasks, such as pattern matching, filtering, sorting, and manipulating data. Its primary use case is to process and manipulate structured data. Therefore, users can leverage its functionalities to perform complex text processing tasks.
How to Use awk Command
As a command-line tool, awk can be utilized in numerous ways. It can either be invoked directly from the command line or incorporated into a shell script. Below are some examples illustrating how to use awk:
Example 1: Counting the Number of Lines in a File
To count the number of lines in a file, you can use the following awk syntax:
awk 'END{print NR}' <name-of-file.txt>
|
In this context, the built-in variable “NR” holds the number of records (lines) processed by awk. The “END” keyword instructs awk to execute the command following it after all lines in the file have been processed. To illustrate this, a text file has been created, and the above syntax has been incorporated into a shell script:
#!/bin/bash
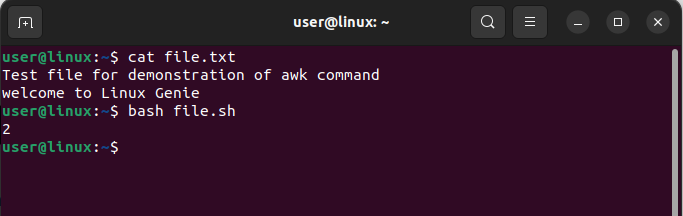
awk 'END{print NR}' file.txt
|
After I created a text file with two lines, I executed the awk command on it and the output displayed the value 2. The text file created for this illustration is depicted in the image below:
Example 2: Filtering Data
To filter data based on specific criteria, the awk command can be utilized with the following syntax:
awk '!/<filter-data>/' <name-of-file.txt> |
As an example, consider the following command, which filters out all lines in a file containing the word “welcome”:
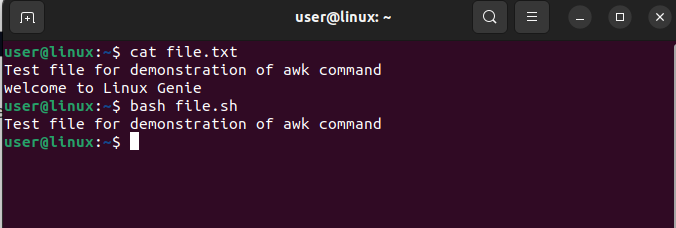
#!bin/bash awk '!/welcome/' file.txt |
The above command shows how to filter out all lines in a file that contain the word “welcome”. The “!” symbol is used to negate the regular expression search, resulting in the printing of all lines that do not contain the word “welcome”. The command uses the same text file as in the previous example and the output is displayed below
Example 3: Extracting Specific Fields
The powerful “awk” command can be used to extract specific fields from a file. For instance, if you want to extract only the names from a file that contains a list of names and addresses, you can use the following command:
awk '{print $<data-field-number>}' <name-of-file.txt>
|
For illustration purposes, I have used the following command to print the first field of the same text file. In this command, “$1” represents the first field in each line of the file, and the “print” command tells awk to print only that field.
#!/bin/bash
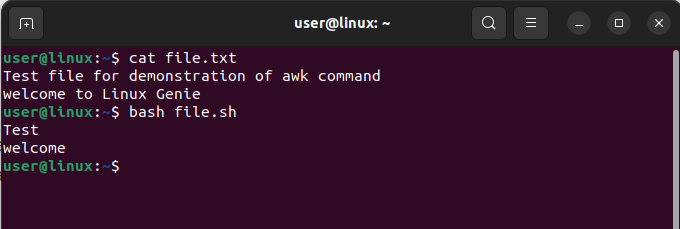
awk '{print $1}' file.txt
|
The given code outputs “Test” (which is the first entry of the first line) and “welcome” (which is the first entry of the second line) from the text file.
Conclusion
Mastering the basics of awk allows users to streamline their workflow and become more efficient and effective Linux or Unix users. A command is a powerful tool that can manipulate and process text files, and perform operations like printing specific columns, searching for patterns, and calculating sums. With its various functions, awk can help users perform various tasks on text files, making it an essential tool to learn.
