
How to Install PySpark on Ubuntu 22.04
PySpark is a powerful framework that combines the simplicity of Python with the scalability of Apache Spark, enabling you to process large-scale data with ease. We’ll take you step-by-step through the installation of PySpark on Ubuntu in this comprehensive guide.
How to Install PySpark on Ubuntu 22.04
Python is one of the programming languages supported by Apache Spark, an open-source engine. You need PySpark in order to use it with Python. Since PySpark is now included with the new versions of Apache Spark, you no longer need to install it separately as a library. However, your computer must be running Python 3.
Additionally, Apache Spark cannot be installed on an Ubuntu 22.04 system without Java being installed. Scala is still a requirement for you. However, it is now included in the Apache Spark package, so installing it individually is no longer necessary. Now let’s go into the installation procedures.
Step 1: Install java on Ubuntu 22.04
You must first install Java if you haven’t already by opening your terminal and upgrading the package repository.
sudo apt install default-jdk -y |

To make sure the installation was successful, check the Java version that was installed:
java --version |

Step 2: Installing Apache Spark
We must obtain the preferred bundle for that from its website. A tar file serves as the package file. We use wget to download it. Use curl or any other appropriate download technique in your situation.
Get the most recent or desired version by visiting the Apache Spark downloads page and note that Scala 2 or later is included with Apache Spark in the most recent version. Consequently, you don’t need to worry about individually installing Scala.
wget https://dlcdn.apache.org/spark/spark-3.3.2/spark-3.3.2-bin-hadoop3-scala2.13.tgz |

Once the download is complete, extract the package using the following command:
tar xvf spark-3.3.2-bin-hadoop3-scala2.13.tgz |

Once the Spark files have been extracted, a new folder containing all of them is created in the current directory. To confirm that we have the new directory, we can list the directory’s contents.
Step 3: Change the directory of the extracted file
The newly formed spark folder should then be transferred to your /opt/spark directory. For this, use the move command.
sudo mv <name-of-folder> /opt/spark |

Step 4: Step up the Environmental variable
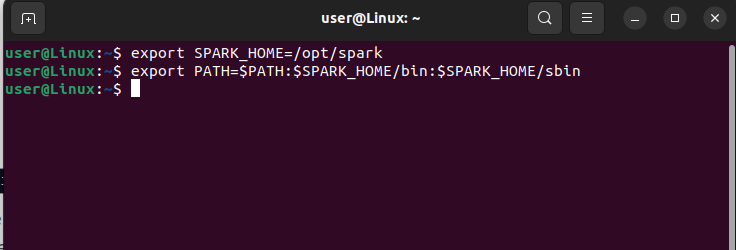
We must set up an environment path variable before we can run Apache Spark on the machine. Enter the following two commands on your terminal to export the environmental paths from the “.bashrc” file:
export SPARK_HOME=/opt/spark export PATH=$PATH:$SPARK_HOME/bin:$SPARK_HOME/sbin |
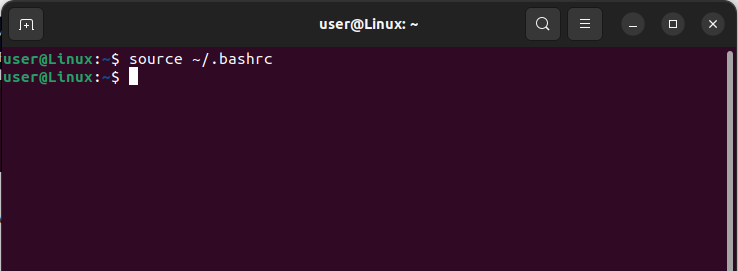
Use the following command to refresh the file and save the environmental variables:
Source ~/.bashrc |
Step 5: Run Pyspark
Run the spark-shell command to launch the spark shell and check if Apache Spark was successfully installed:
spark-shell |
Depending on the task you wish to complete, not everyone like the Scala interface, so check to see if PySpark is also installed by typing the pyspark command into your terminal.
pyspark |
It ought to launch the PySpark shell, from which you can begin running the various scripts and developing applications that make use of PySpark.

Example code for testing installation of PySpark
Run a quick test to make sure PySpark is installed properly and for that use the below example code:
from pyspark.sql import SparkSession
spark = SparkSession.builder \
.appName("PySparkTest") \
.getOrCreate()
spark.range(10).show()
spark.stop()
|
If PySpark is installed correctly, you should see a table-like output displaying numbers from 0 to 9 as n the figure below:

Conclusion
Installing PySpark on your Ubuntu system empowers you to utilize the capabilities of Apache Spark for big data analytics. By following the step-by-step guide outlined in this article, you can seamlessly install PySpark and leverage its powerful features for scalable data processing tasks.
